matplotlib.axes.Axes.hist #
- Assi. hist ( x , bins = None , range = None , density = False , weights = None , cumulative = False , bottom = None , histtype = 'bar' , align = 'mid' , direction = 'vertical' , rwidth = None , log = Falso , colore = Nessuno, label = None , stacked = False , * , data = None , ** kwargs ) [fonte] #
Calcolare e tracciare un istogramma.
Questo metodo utilizza
numpy.histogramper raggruppare i dati in x e contare il numero di valori in ogni bin, quindi disegna la distribuzione come aBarContaineroPolygon. I parametri bin , range , densità e pesi vengono inoltrati anumpy.histogram.Se i dati sono già stati raggruppati e contati, utilizzare
barostairsper tracciare la distribuzione:counts, bins = np.histogram(x) plt.stairs(bins, counts)
In alternativa, traccia i bin e i conteggi precalcolati utilizzando
hist()trattando ogni bin come un singolo punto con un peso uguale al suo conteggio:plt.hist(bins[:-1], bins, weights=counts)
L'input di dati x può essere un array singolare, un elenco di set di dati di lunghezze potenzialmente diverse ([ x0 , x1 , ...]) o un ndarray 2D in cui ogni colonna è un set di dati. Si noti che la forma ndarray è trasposta rispetto alla forma lista. Se l'input è un array, il valore restituito è una tupla ( n , bins , patches ); se l'input è una sequenza di array, il valore restituito è una tupla ([ n0 , n1 , ...], bins , [ patches0 , patches1 , ...]).
Gli array mascherati non sono supportati.
- Parametri :
- x (n,) matrice o sequenza di (n,) matrici
Valori di input, accetta un singolo array o una sequenza di array che non devono necessariamente avere la stessa lunghezza.
- bins int o sequenza o str, predefinito:
rcParams["hist.bins"](predefinito:10) Se bins è un numero intero, definisce il numero di bin di uguale larghezza nell'intervallo.
Se bins è una sequenza, definisce i bordi del bin, compreso il bordo sinistro del primo bin e il bordo destro dell'ultimo bin; in questo caso, i cestini possono essere distanziati in modo disuguale. Tutti i contenitori tranne l'ultimo (più a destra) sono semiaperti. In altre parole, se bin è:
[1, 2, 3, 4]
quindi il primo bin è (incluso 1, ma escluso 2) e il secondo . L'ultimo contenitore, tuttavia, è , che include 4.
[1, 2)[2, 3)[3, 4]Se bins è una stringa, è una delle strategie di binning supportate da
numpy.histogram_bin_edges: 'auto', 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges' o 'sqrt'.- tupla di intervallo o Nessuno, impostazione predefinita: Nessuno
La gamma inferiore e superiore dei contenitori. I valori anomali inferiore e superiore vengono ignorati. Se non fornito, l'intervallo è . L'intervallo non ha effetto se bins è una sequenza.
(x.min(), x.max())Se bins è una sequenza o viene specificato un intervallo , il ridimensionamento automatico si basa sull'intervallo di bin specificato anziché sull'intervallo di x.
- densità bool, predefinito: falso
Se
True, disegna e restituisce una densità di probabilità: ogni bin visualizzerà il conteggio grezzo del bin diviso per il numero totale di conteggi e la larghezza del bin ( ), in modo che l'area sotto l'istogramma si integri a 1 ( ).density = counts / (sum(counts) * np.diff(bins))np.sum(density * np.diff(bins)) == 1Se stacked è anche
True, la somma degli istogrammi viene normalizzata a 1.- pesi (n,) tipo matrice o Nessuno, impostazione predefinita: Nessuno
Un array di pesi, della stessa forma di x . Ogni valore in x contribuisce solo con il proprio peso associato al conteggio bin (invece di 1). Se la densità è
True, i pesi vengono normalizzati, in modo che l'integrale della densità nell'intervallo rimanga 1.- bool cumulativo o -1, predefinito: Falso
Se
True, viene calcolato un istogramma in cui ogni bin fornisce i conteggi in quel bin più tutti i bin per i valori più piccoli. L'ultimo bin fornisce il numero totale di datapoint.Se anche la densità è
Trueallora l'istogramma viene normalizzato in modo tale che l'ultimo bin sia uguale a 1.Se cumulativo è un numero minore di 0 (ad esempio, -1), la direzione dell'accumulazione è invertita. In questo caso, se anche la densità è
True, l'istogramma viene normalizzato in modo tale che il primo bin sia uguale a 1.- inferiore simile a un array, scalare o Nessuno, impostazione predefinita: Nessuno
Posizione del fondo di ciascun contenitore, ad es. i contenitori vengono estratti da
bottoma Se uno scalare, la parte inferiore di ciascun contenitore viene spostata della stessa quantità. Se si tratta di un array, ogni bin viene spostato in modo indipendente e la lunghezza della parte inferiore deve corrispondere al numero di bin. Se Nessuno, il valore predefinito è 0.bottom + hist(x, bins)- histtype {'bar', 'barstacked', 'step', 'stepfilled'}, default: 'bar'
Il tipo di istogramma da disegnare.
'bar' è un tradizionale istogramma a barre. Se vengono forniti più dati, le barre vengono disposte una accanto all'altra.
'barstacked' è un istogramma di tipo barra in cui più dati sono impilati uno sopra l'altro.
'step' genera un grafico a linee che per impostazione predefinita è vuoto.
'stepfilled' genera un grafico lineare che è riempito per impostazione predefinita.
- align {'left', 'mid', 'right'}, default: 'mid'
L'allineamento orizzontale delle barre dell'istogramma.
'left': le barre sono centrate sui bordi del bin di sinistra.
'mid': le barre sono centrate tra i bordi del bin.
'right': le barre sono centrate sui bordi del bin di destra.
- orientamento {'verticale', 'orizzontale'}, predefinito: 'verticale'
Se 'horizontal',
barhverrà utilizzato per istogrammi di tipo barra e il kwarg inferiore sarà il bordo sinistro.- rwidth float o Nessuno, default: Nessuno
La larghezza relativa delle barre come frazione della larghezza del bin. If
None, calcola automaticamente la larghezza.Ignorato se histtype è 'step' o 'stepfilled'.
- log bool, predefinito: falso
Se
True, l'asse dell'istogramma verrà impostato su una scala logaritmica.- color colore o simile a una matrice di colori o Nessuno, impostazione predefinita: Nessuno
Colore o sequenza di colori, uno per set di dati. Predefinito (
None) utilizza la sequenza di colori delle linee standard.- label str o Nessuno, predefinito: Nessuno
Stringa o sequenza di stringhe per corrispondere a più set di dati. I grafici a barre producono più patch per set di dati, ma solo il primo ottiene l'etichetta, quindi
legendfunzionerà come previsto.- bool in pila , predefinito: Falso
If
True, più dati sono impilati uno sopra l'altro SeFalsepiù dati sono disposti fianco a fianco se histtype è 'bar' o uno sopra l'altro se histtype è 'step'
- Resi :
- n matrice o elenco di matrici
I valori dei contenitori dell'istogramma. Vedere densità e pesi per una descrizione della possibile semantica. Se l'input x è un array, questo è un array di lunghezza nbins . Se l'input è una sequenza di array , questo è un elenco di array con i valori degli istogrammi per ciascuno degli array nello stesso ordine. Il dtype dell'array n (o dei suoi array di elementi) sarà sempre float anche se non viene utilizzata alcuna ponderazione o normalizzazione.
[data1, data2, ...]- matrice di contenitori
I bordi dei cassonetti. Lunghezza nbins + 1 (nbins bordi sinistro e bordo destro dell'ultimo bin). Sempre un singolo array anche quando vengono passati più set di dati.
- patch
BarContainero elenco di un singoloPolygono elenco di tali oggetti Contenitore di singoli artisti utilizzato per creare l'istogramma o l'elenco di tali contenitori se sono presenti più set di dati di input.
- Altri parametri :
- oggetto indicizzabile dei dati , facoltativo
Se forniti, i seguenti parametri accettano anche una stringa
s, che viene interpretata comedata[s](a meno che ciò non sollevi un'eccezione):x , pesi
- **kwargs
Patchproprietà
Guarda anche
Appunti
Per un numero elevato di bin (>1000), il tracciato può essere notevolmente più veloce se histtype è impostato su 'step' o 'stepfilled' piuttosto che su 'bar' o 'barstacked'.
Esempi che utilizzano matplotlib.axes.Axes.hist#

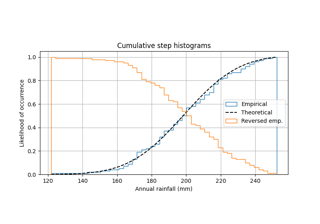
Utilizzo di istogrammi per tracciare una distribuzione cumulativa
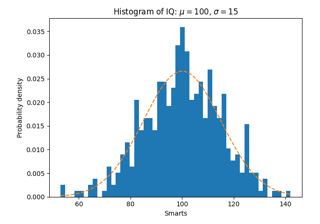
Alcune caratteristiche della funzione istogramma (hist).
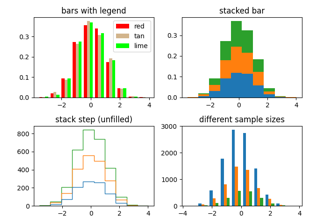
La funzione dell'istogramma (hist) con più insiemi di dati
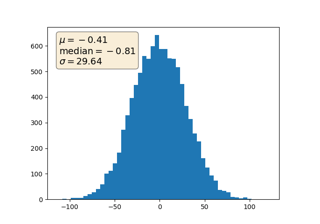
Metodi bayesiani per il foglio di stile degli hacker